Tengo esta conversación una y otra vez con dos tipos de personas. La primera es un colega en una empresa que quiere llevar IA a un proyecto concreto. La segunda es un investigador o consultor independiente que necesita ayuda de IA en una consultoría puntual con datos sensibles de un cliente. Los dos chocan con la misma pared en dos minutos: parece que la elección fuera pegar sus datos en un chatbot público y cruzar los dedos, o montar un rack de GPUs que nadie va a operar. Esa no es la elección real. Hay una tercera opción. Es la que la mayoría de las empresas y la mayoría de los consultores independientes debería evaluar primero, y casi nadie la explica con suficiente claridad. Este artículo es esa explicación.
La falsa elección
Imagina dos escenarios. Una empresa construyendo un asistente interno que responde preguntas sobre documentos de políticas. Un consultor contratado por tres meses para extraer hallazgos estructurados de mil transcripciones confidenciales de entrevistas. Los dos proyectos son reales, los datos son sensibles de formas distintas, y ninguna de las dos personas tiene interés en convertirse en operador de infraestructura.
Las dos primeras opciones que aparecen encajan mal. El chatbot público es rápido para empezar, pero envía datos a un producto de consumo con poco control sobre cómo se procesan o cómo quedan registrados. Tener hardware propio significa comprar o alquilar GPUs, instalar modelos, operar el clúster y vigilar capacidad, parches, seguridad, colas y costos. Eso da control, pero es caro, lento de montar, y te compromete a operar infraestructura que no tiene nada que ver con tu trabajo real.
La mayoría de las empresas y la mayoría de los consultores no necesita ninguna de las dos. Necesita el tercer camino.
El concepto: inferencia gestionada
El tercer camino es la inferencia gestionada. Alquilas el modelo en ejecución, no el hardware sobre el que corre.
Una definición rápida de las piezas. Un modelo de IA entrenado es, en la práctica, un archivo muy grande lleno de parámetros numéricos aprendidos, normalmente llamados pesos. Esos pesos representan lo aprendido por el modelo, congelado en forma matemática. Ejecutar ese archivo para obtener una respuesta se llama inferencia, y la inferencia es la parte que necesita GPUs y cuesta dinero.
Con la inferencia gestionada, alguien más tiene las GPUs y mantiene los pesos cargados y listos. Tú envías un prompt por una API, esa infraestructura ejecuta la inferencia, y recibes una respuesta. Pagas por uso. Sin clúster, sin instalar modelos, sin GPU que cuidar.
Dos productos llevan esta idea en direcciones muy distintas. Amazon Bedrock aloja modelos de frontera como Claude y, actualmente en preview, modelos de frontera de OpenAI, además de modelos de Amazon y otros proveedores. Ese camino encaja con clientes que necesitan calidad de primer nivel con controles fuertes de residencia y gobernanza. DigitalOcean Gradient aloja modelos open-weight hospedados por DigitalOcean, como Llama, Mistral y DeepSeek, para clientes que no necesitan calidad de frontera pero quieren inferencia dentro de un único perímetro de nube. No compiten. Resuelven problemas diferentes para necesidades diferentes.
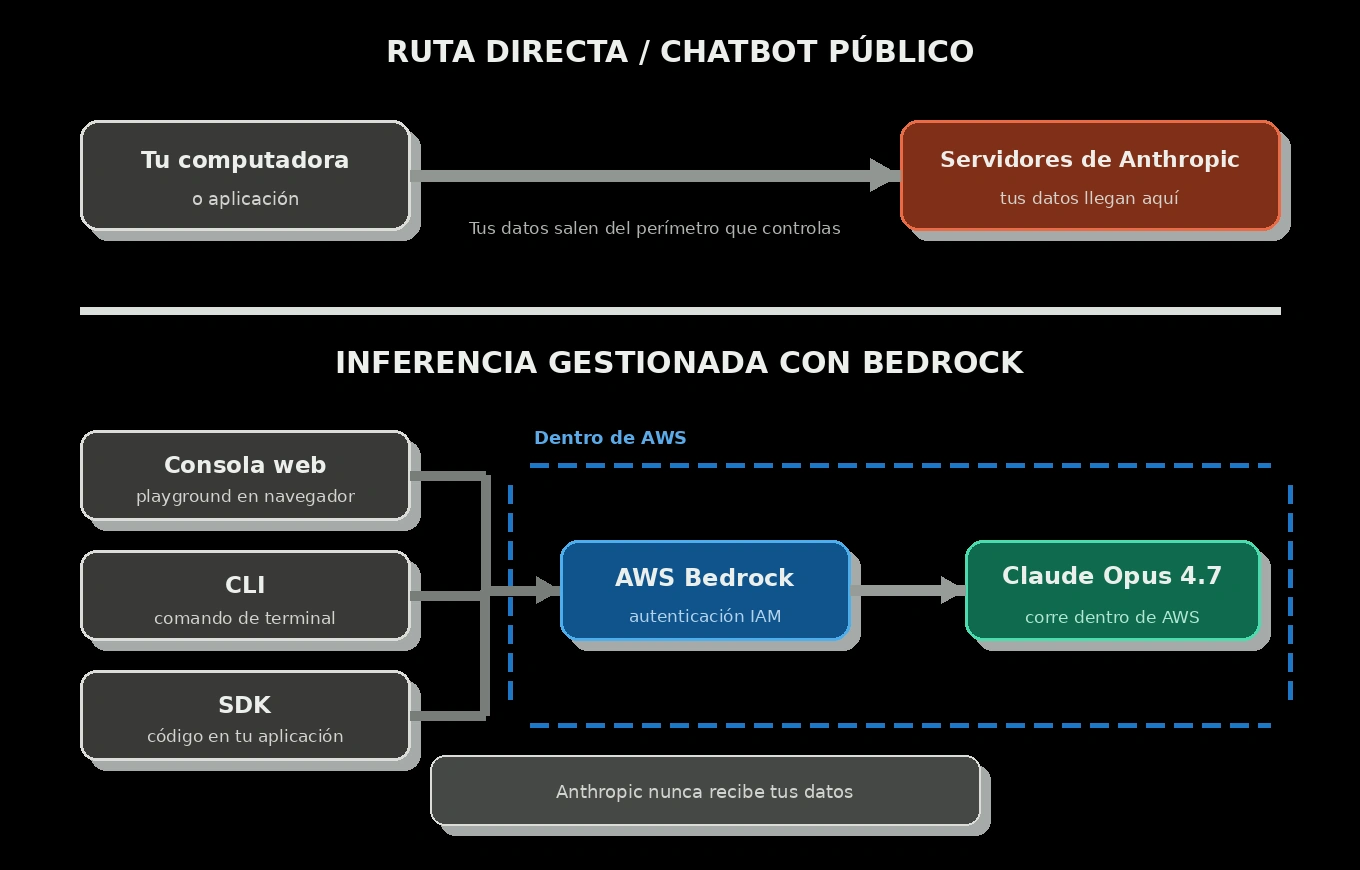
AWS Bedrock: modelos de frontera con soberanía de datos
Amazon Bedrock ejecuta modelos de frontera, incluido Claude Opus 4.7, sobre infraestructura de AWS. Cuando envías un prompt, viaja a AWS, la inferencia corre dentro del perímetro de AWS y la respuesta vuelve. La distinción importante es que Bedrock no actúa como un proxy hacia Anthropic: el proveedor del modelo no recibe tus prompts ni tus respuestas.
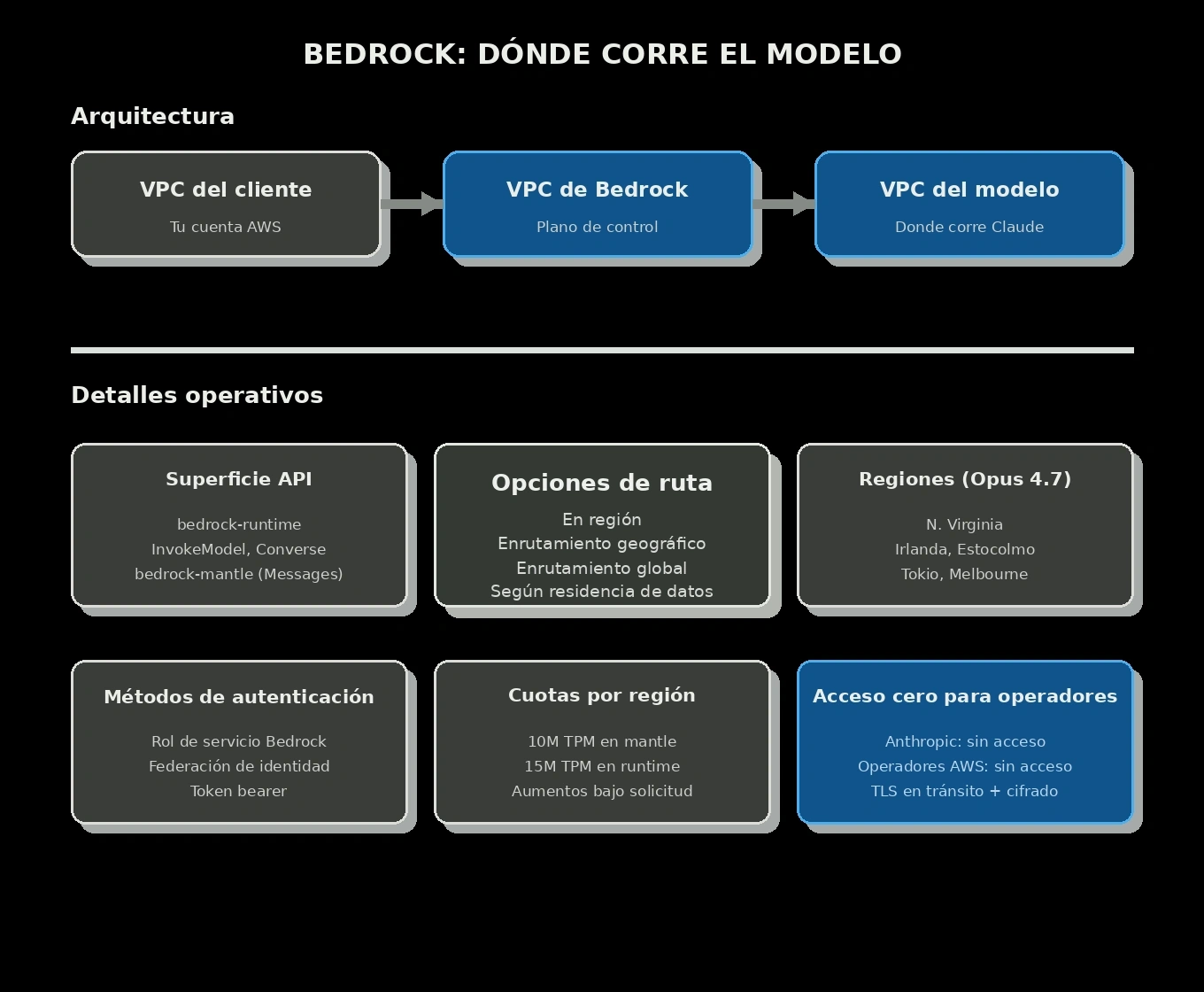
El aislamiento es arquitectónico, no solo contractual. Tu cuenta, el plano de control de Bedrock y la flota que ejecuta el modelo están separados y conectados mediante rutas privadas dentro de AWS. AWS documenta que los proveedores de modelos no tienen acceso a las cuentas de despliegue de Bedrock, a los logs, a los prompts de clientes ni a las completions. En la ruta de Claude Opus 4.7, AWS también describe un diseño de zero operator access: ni Anthropic ni operadores de AWS pueden ver prompts y respuestas en tiempo de inferencia. El tráfico va cifrado, y Bedrock ofrece varias opciones de inferencia y enrutamiento: En región, Geográfico Cross-Region y Global Cross-Region. Eliges según tus requisitos de residencia de datos y rendimiento.
Cómo corre el modelo sobre hardware que no es tuyo
Vale la pena ser preciso sobre lo que ocurre de verdad, porque de ahí viene la confianza en los datos.
Los pesos del modelo son un archivo. El proveedor entrega el modelo y su software de inferencia a la plataforma bajo un acuerdo comercial. La plataforma despliega una copia en su propia infraestructura y ejecuta la inferencia allí. No hay reenvío de cada prompt al proveedor en el momento de la petición. Si lo hubiera, toda la historia de aislamiento se vendría abajo, porque cada prompt tocaría los sistemas del proveedor.
Es parecido al ciclo de vida de una imagen de contenedor. Alguien la construye, la publica, y un servidor en algún sitio la descarga y la ejecuta. El autor de la imagen no ve lo que hace el contenedor en producción. Claude en Bedrock funciona con la misma lógica, aunque con un archivo mucho más grande y propietario: Anthropic entrega el modelo a AWS, AWS lo ejecuta sobre infraestructura de AWS, y lo que pasa durante la petición queda entre AWS y su cliente.
DigitalOcean Gradient: modelos open con soberanía de datos
DigitalOcean Gradient toma un enfoque distinto para una necesidad distinta. Aloja modelos open-weight, incluidos Llama de Meta, Mistral y DeepSeek, directamente sobre infraestructura de DigitalOcean. Cuando llamas a uno de esos modelos hospedados por DigitalOcean, tu prompt va a la API de DigitalOcean y la inferencia corre sobre hardware de DigitalOcean. Los autores del modelo no están en la ruta de inferencia.
Hay un matiz importante. Gradient también ofrece acceso a modelos comerciales de proveedores como Anthropic y OpenAI, pero en ese caso DigitalOcean actúa como pass-through hacia el proveedor original. DigitalOcean indica que no almacena entradas ni salidas para ningún modelo, y que los datos enviados a modelos hospedados por DigitalOcean no se usan para entrenar, reentrenar o fine-tunear modelos en la plataforma de DigitalOcean, ni se comparten con terceros para esos fines. Para las discusiones de soberanía, este artículo trata el lado de modelos open hospedados por DigitalOcean: Llama, Mistral y DeepSeek corriendo sobre infraestructura de DigitalOcean. Ahí es donde la arquitectura dentro del perímetro aplica de forma más directa.
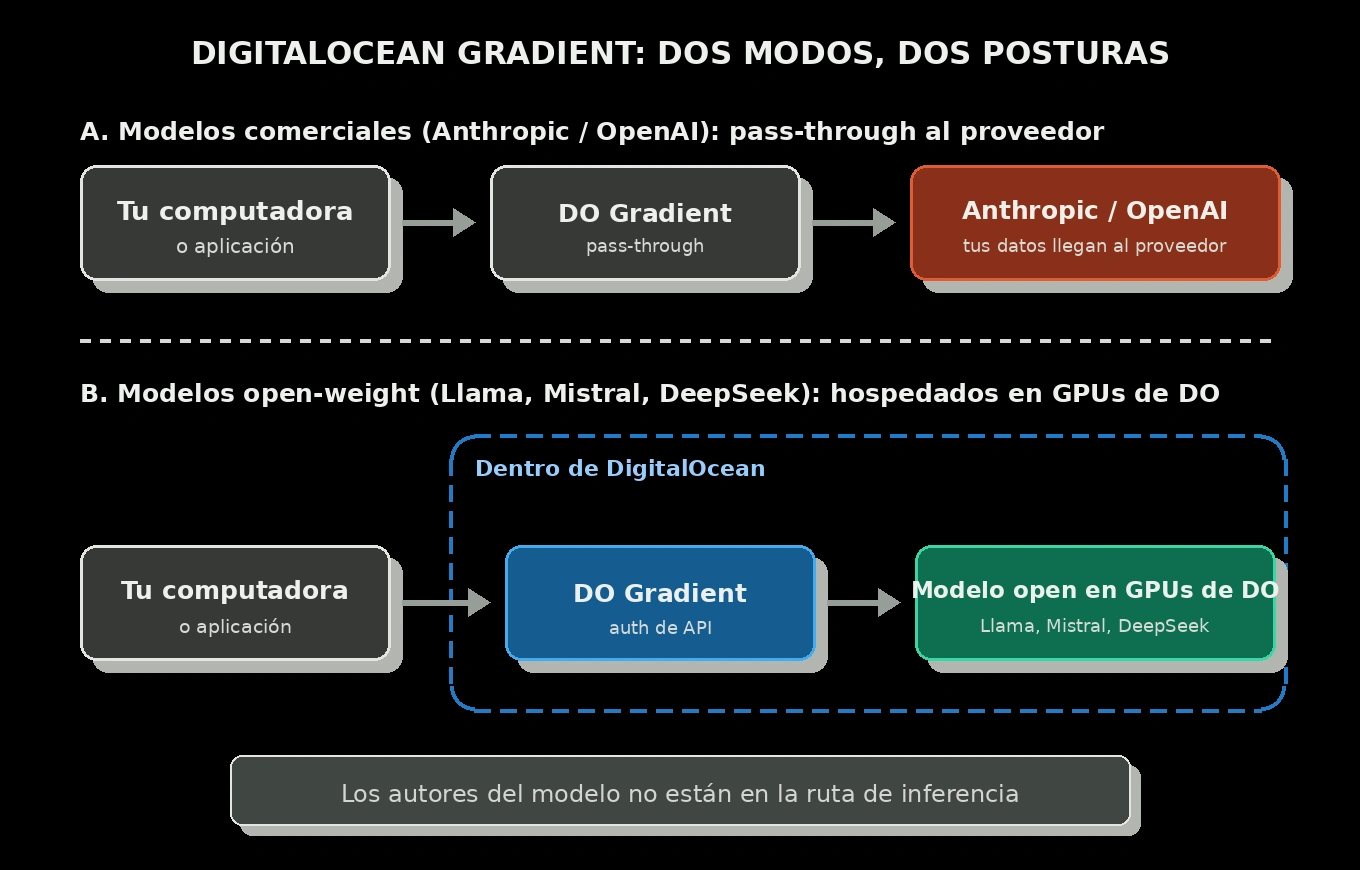
Así que Gradient no es un competidor de Bedrock. Bedrock resuelve “necesito un modelo de frontera y soberanía de datos”. Gradient con modelos open resuelve “necesito un modelo competente para esta tarea específica y soberanía de datos sin salir de un único perímetro de nube”. Problemas diferentes, productos diferentes.
Emparejar tus datos con la opción correcta
La estrategia de protección es directa una vez que clasificas lo que tienes.
Material público o de baja sensibilidad funciona en cualquiera de las dos opciones. Elige según necesidades de calidad y presupuesto. Si la tarea es difícil y la calidad importa, usa Bedrock con Claude o similar. Si la tarea es moderada y el presupuesto importa más, usa Gradient con un modelo open.
Material regulado o genuinamente sensible necesita más cuidado. Si la tarea requiere calidad de frontera (razonamiento profundo, síntesis compleja, flujos agénticos), usa Bedrock con una opción En región o Geográfica anclada a una geografía que aceptes. Tus datos se quedan dentro de AWS, el proveedor del modelo no los ve, y puedes demostrar residencia a auditores. Si la tarea puede servirse con un modelo open (extracción, clasificación, RAG sobre documentos, redacción de respuestas de soporte interno), usa Gradient con un modelo open hospedado por DigitalOcean. Tus datos se quedan en el entorno de inferencia de DigitalOcean, ningún autor de modelo separado entra en la ruta de la petición, y normalmente pagas menos por token.
El error es saltarse la clasificación y enrutar todo a lo que sea más fácil de integrar, para luego descubrir que parte de eso no debería haber ido por ahí.
Casos de uso que encajan con este modelo
Algunos ejemplos concretos para hacerlo real.
Una empresa construyendo un asistente de documentos interno sobre archivos de políticas. Recuperación sobre una base de conocimiento privada, respuestas redactadas por el modelo. La calidad de frontera importa si las preguntas son complejas; un modelo open funciona bien si las preguntas son estándar.
Un equipo de soporte usando un modelo para redactar respuestas a tickets entrantes que un humano revisa. Un modelo open en Gradient suele bastar, y la diferencia de costo importa con volumen.
Un equipo de desarrollo usando un asistente de código acotado a una base de código interna. Modelos de frontera en Bedrock cuando el trabajo involucra razonamiento arquitectónico complejo; modelos open en Gradient para revisión de código rutinaria y generación de boilerplate.
Un trabajo por lotes que clasifica documentos o extrae datos estructurados durante la noche. Los modelos open suelen ser suficientes, y los precios de batch en cargas compatibles pueden recortar más la factura.
Un investigador o consultor independiente en un encargo de tres meses con datos confidenciales de un cliente. Este es el caso donde la inferencia gestionada se gana su nombre. El investigador no quiere comprar GPUs para un proyecto temporal, y el cliente no quiere que los datos salgan de un perímetro controlado. Si el análisis requiere razonamiento de frontera (síntesis compleja, juicios con matiz, argumentación de varios pasos), Bedrock con una opción En región dentro de la jurisdicción del cliente es la decisión correcta. Si el trabajo es más mecánico (extracción estructurada, detección de patrones en transcripciones, resumen), un modelo open en Gradient cuesta una fracción y puede mantener la ruta de inferencia dentro de DigitalOcean. Cuando termina el encargo, no queda infraestructura corriendo ni una compra de hardware que amortizar.
Cada uno de estos es un proyecto acotado. Ninguno justifica operar un clúster de GPUs por sí mismo.
El ejercicio de costos
Los números hacen concreta la decisión. Toma una empresa mediana con un asistente de documentos interno. Supón 1.000 consultas al día en toda la empresa, cada consulta con unos 4.000 tokens de entrada para el prompt de sistema más el contexto recuperado, y unos 600 tokens de salida para la respuesta. En un mes de 30 días son 120 millones de tokens de entrada y 18 millones de tokens de salida.
| Opción | Entrada ($/M) | Salida ($/M) | Costo mensual estimado | Dónde viven los datos |
|---|---|---|---|---|
| Bedrock — Claude Opus 4.7 | $5,00 | $25,00 | ~$1.050 | Dentro de AWS, ruta con acceso cero para operadores |
| Bedrock — Claude Sonnet 4.6 | $3,00 | $15,00 | ~$630 | Dentro de AWS, ruta con acceso cero para operadores |
| Bedrock — Claude Haiku 4.5 | $1,00 | $5,00 | ~$210 | Dentro de AWS, ruta con acceso cero para operadores |
| DigitalOcean — Llama 3.3 70B alojado | ~$0,65 | ~$0,65 | ~$90 | Dentro de DigitalOcean |
| Autogestionado — una NVIDIA H100 24/7 | n/a | n/a | ~$2.400–$5.000+ | Tu propio entorno |
Saltan a la vista varias cosas. La misma carga de trabajo puede ir de unos $90 a unos $1.050 al mes solo por cambiar el nivel de modelo. Usar por defecto el modelo más potente es la forma más común de pagar de más. La fila de la GPU autogestionada es un costo fijo que pagas esté la máquina ocupada u ociosa. En este volumen queda por encima de las opciones gestionadas, y una sola H100 ni siquiera te da acceso a un modelo propietario de frontera porque esos pesos no están disponibles para autohospedar. El rango de la H100 depende del proveedor, la región, la modalidad on-demand o reservada, el almacenamiento, la red y la operación.
Para el caso del investigador la matemática es aún más llamativa. Un consultor procesando 500 documentos en tres meses podría generar 5 a 10 millones de tokens en total. En Sonnet 4.6 a través de Bedrock eso normalmente cae en decenas de dólares para cargas de extracción o resumen, y puede subir a poco más de cien dólares si el trabajo genera mucha salida o hace varias pasadas. En Llama 3.3 70B a través de Gradient, la factura de tokens del modelo normalmente queda por debajo de diez dólares antes de costos adicionales de plataforma, almacenamiento u orquestación. En cualquiera de los dos casos cuesta menos que mantener una H100 corriendo continuamente para un encargo corto.
Dos matices mantienen la tabla honesta. Primero, el caché de prompts puede reducir con fuerza la parte de entrada cuando el prompt de sistema y el contexto estable se repiten. Después de escribir la caché, las lecturas pueden costar una fracción de la entrada normal. Segundo, el procesamiento por lotes puede reducir la factura de tokens en cargas que toleran minutos de latencia. Del otro lado, una base de conocimiento gestionada añade costos propios de embeddings, almacenamiento vectorial, guardrails u observabilidad. En cargas pequeñas esos costos fijos pueden pesar más que los tokens del modelo. Las opciones Regionales, Geográficas y Globales también pueden tener precios distintos. AWS describe Global Cross-Region como una opción con alrededor de 10% de ahorro frente a Geographic Cross-Region, mientras Anthropic documenta multiplicadores de residencia de datos separados en sus propias plataformas. Confirma la página de precios vigente antes de presupuestar.
Hacia dónde va esto
La dirección del viaje está documentada en las tarifas vigentes, los anuncios oficiales y los despliegues de infraestructura verificables.
Los precios de los modelos de frontera han caído con fuerza en el nivel superior. La página vigente de precios de Anthropic lista modelos anteriores del nivel Opus 4 a $15 de entrada y $75 de salida por millón de tokens, mientras Claude Opus 4.7 se sitúa en $5 y $25 por millón de tokens. Es una reducción del 66,7% en el nivel premium. Sonnet y Haiku también ofrecen niveles más baratos, lo que hace innecesario usar siempre el modelo más caro. El argumento económico para autohospedar un modelo equivalente a uno de frontera se debilita a medida que mejora la inferencia gestionada.
Se está construyendo infraestructura soberana, con vacíos honestos que hay que revisar al diseñar. AWS lanzó la European Sovereign Cloud como una partición física y lógicamente separada en Brandenburgo, Alemania, respaldada por una inversión de €7.800 millones. AWS indica que Bedrock está incluido entre los servicios disponibles en ese entorno soberano. El punto práctico importante es que disponibilidad del servicio y disponibilidad de modelos no son lo mismo: al diseñar una arquitectura soberana con Bedrock, verifica el catálogo vigente de modelos en la matriz oficial de capacidades de AWS antes de comprometerte.
Las opciones de endpoint y enrutamiento se han convertido en preocupaciones arquitectónicas de primera clase. Bedrock documenta opciones En región, Geographic Cross-Region y Global Cross-Region para Claude Opus 4.7. Hace dos años esa distinción apenas existía en las conversaciones de producto. Hoy es una de las primeras decisiones que tomas después de elegir el modelo.
Capacidad que antes era premium se está volviendo estándar. La documentación de precios de Anthropic indica que Opus 4.7, Opus 4.6 y Sonnet 4.6 incluyen la ventana completa de 1 millón de tokens a precio estándar. La misma página también advierte que Opus 4.7 usa un nuevo tokenizador que puede consumir hasta 35% más tokens para el mismo texto fijo. Por eso conviene medir antes de migrar cargas desde versiones anteriores.
La imagen combinada es directa. Alquilar inferencia de frontera sigue abaratándose. Los controles de residencia y enrutamiento se vuelven más granulares. Autohospedar solo tiene sentido en la franja estrecha donde la regulación, la latencia o el costo a escala extrema fuerzan la decisión.
Cómo decidir
Un marco corto para cerrar. Clasifica la sensibilidad de tus datos antes que nada. Empareja cada carga de trabajo con el modelo más pequeño que haga bien el trabajo, en lugar de usar por defecto el más potente. Elige la plataforma según dónde se permite que vivan los datos: Bedrock con una opción En región o Geográfica para trabajo sensible con modelos de frontera, o un modelo open hospedado por DigitalOcean en Gradient cuando la tarea no requiera calidad de frontera. Empieza con pago por uso y optimiza después con caché, lotes y enrutamiento cuando veas el uso real.
Tener GPUs propias solo tiene sentido con volumen alto y sostenido, requisitos muy específicos de latencia o costo, o una obligación absoluta de aislamiento. Para una empresa con un proyecto bien definido, o un investigador con un encargo confidencial, la inferencia gestionada es el punto de partida correcto. Los datos pueden quedar bien protegidos siempre que la arquitectura se elija antes de mandar el primer prompt.
Por: Cesar Rosa Polanco - Escrito a partir de una experiencia real, con asistencia de inteligencia artificial como herramienta de apoyo editorial.