I keep having this conversation with two types of people. The first is a colleague at a company who wants to bring AI into a specific project. The second is an independent consultant who needs AI help on a one-off engagement with sensitive client data. Both run into the same wall within two minutes: it seems like the choice is either pasting their data into a public chatbot and hoping for the best, or standing up a rack of GPUs that nobody will operate. That is not the real choice. There is a third option. It is the one most companies and most consultant should evaluate first, and almost nobody explains it clearly enough. This article is that explanation.
The false choice
Picture two scenarios. A company building an internal assistant that answers questions over policy documents. A consultant hired for a three-month engagement to extract structured findings from a thousand confidential interview transcripts. Both projects are real, the data is sensitive in different ways, and neither person has any interest in becoming an infrastructure operator.
The first two options that come to mind are both poor fits. The public chatbot is fast to start, but it sends data into a consumer product with limited control over how it is processed or logged. Owning the hardware means buying or renting GPUs, installing models, operating the cluster, and managing capacity, patches, queues, and costs. That gives control, but it is expensive, slow to set up, and it commits you to operating infrastructure that has nothing to do with your actual work.
Most companies and most consultants do not need either. They need the third path.
The concept: managed inference
The third path is managed inference. You rent the running model, not the hardware it runs on.
A quick definition of the moving parts. A trained AI model is, practically speaking, a very large file full of learned numerical parameters called weights. Those weights represent what the model learned, frozen in mathematical form. Running that file to produce an answer is called inference, and inference is the part that needs GPUs and costs money.
With managed inference, someone else owns the GPUs and keeps the weights loaded and ready. You send a prompt over an API, that infrastructure runs the inference, and you get a response back. You pay per use. No cluster, no model installation, no GPU to babysit.
Two products take this idea in very different directions. Amazon Bedrock hosts frontier models such as Claude and, currently in preview, OpenAI frontier models, along with models from Amazon and other providers. That path fits customers who need top-tier quality with strong residency and governance controls. DigitalOcean Gradient hosts DigitalOcean-hosted open-weight models such as Llama, Mistral, and DeepSeek for customers who do not need frontier-tier quality but want inference inside a single cloud perimeter. They are not competitors. They solve different problems for different needs.
AWS Bedrock: frontier models with data sovereignty
Amazon Bedrock runs frontier models, including Claude Opus 4.7, on AWS infrastructure. When you send a prompt, it travels to AWS, inference runs inside the AWS perimeter, and the response comes back. The important distinction is that Bedrock is not a proxy to Anthropic: the model provider does not receive your prompts or responses.
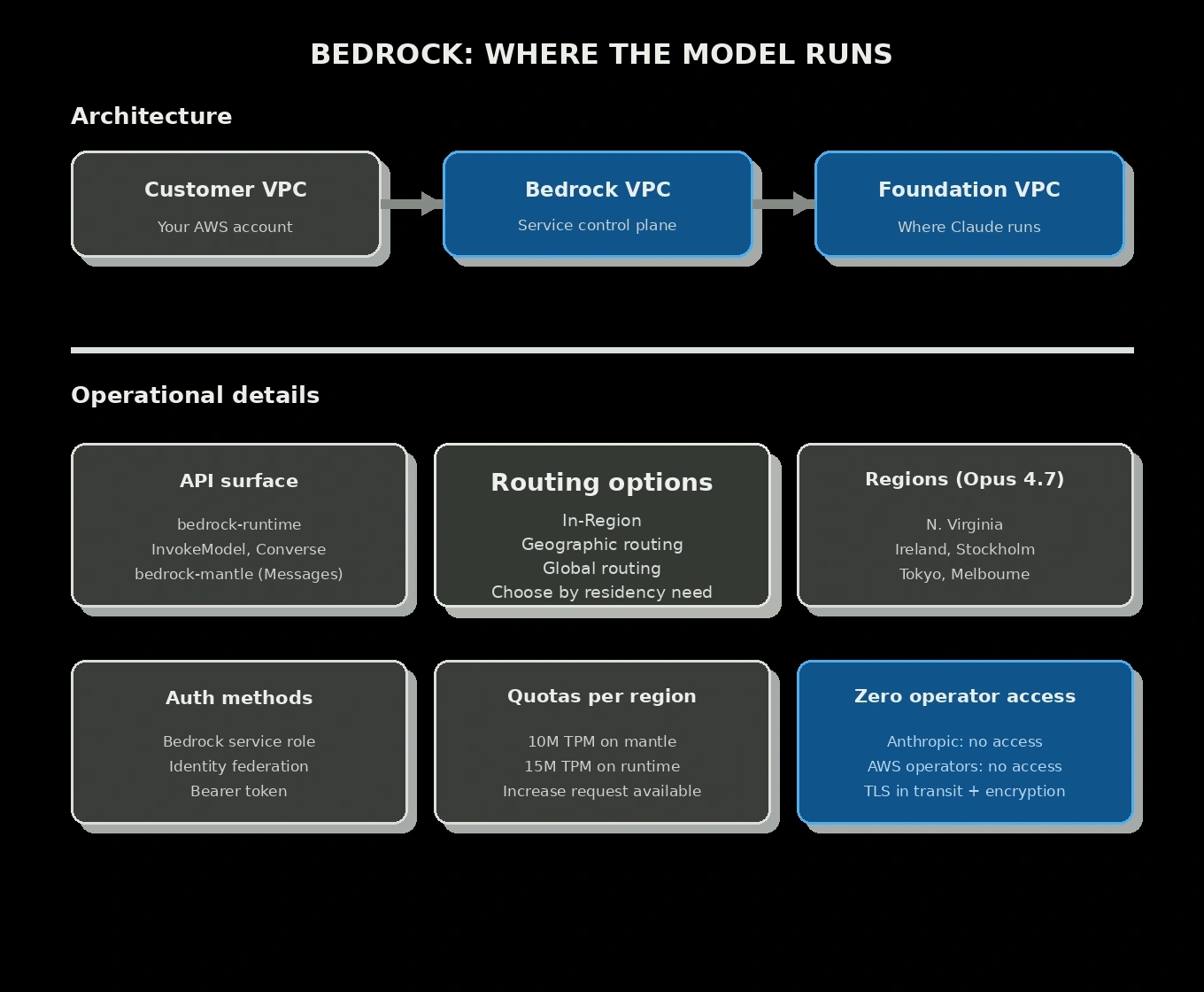
The isolation is architectural, not just contractual. Your account, the Bedrock control plane, and the fleet that runs the model are separated and connected through private paths inside AWS. AWS documents that model providers do not have access to Bedrock deployment accounts, logs, customer prompts, or completions. On the Claude Opus 4.7 path, AWS also describes a zero operator access design: neither Anthropic nor AWS operators can view prompts and responses at inference time. Traffic is encrypted, and Bedrock exposes multiple inference and routing options: In-Region, Geographic Cross-Region, and Global Cross-Region. You choose based on your data residency and throughput requirements.
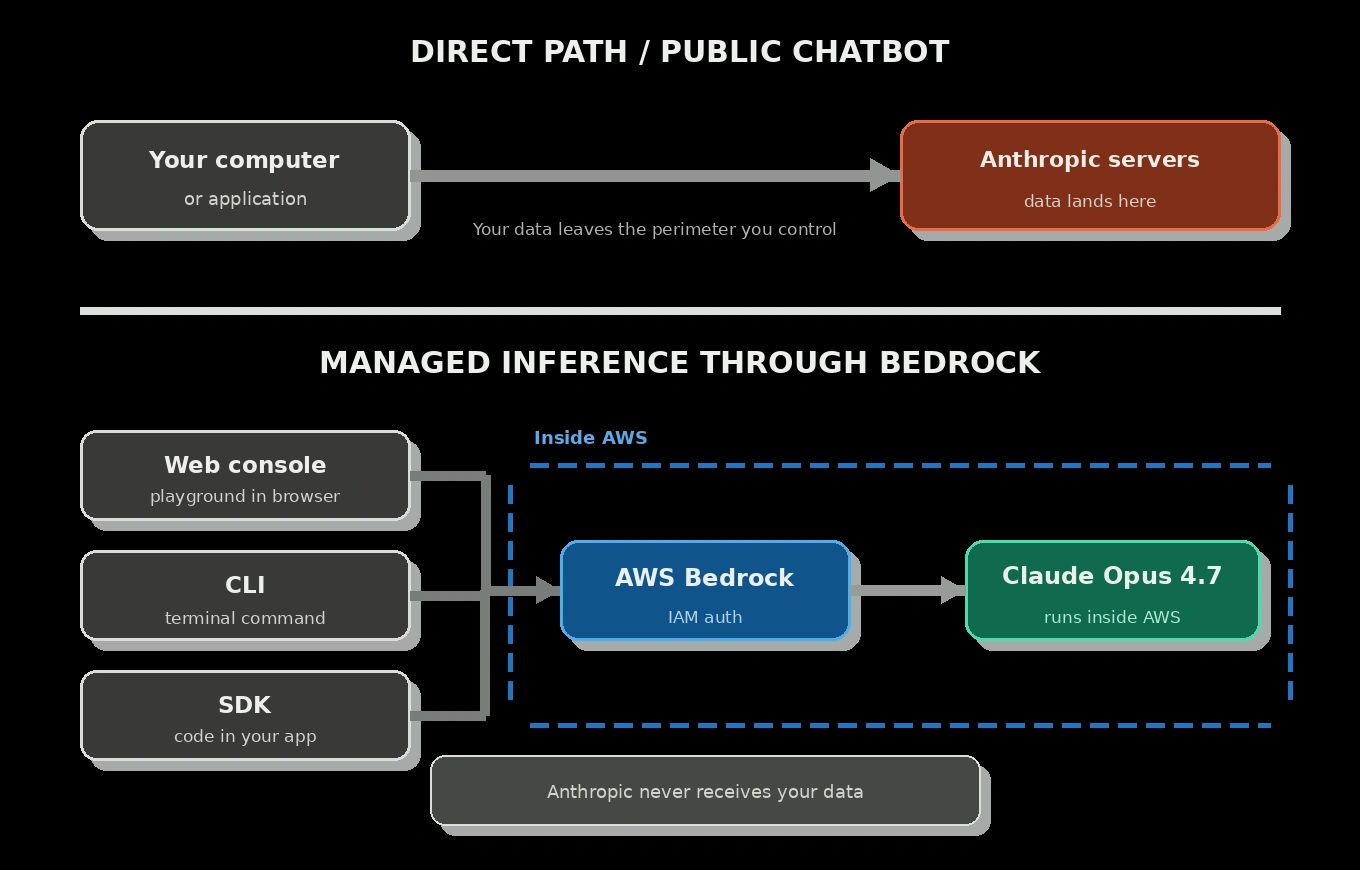
How the model runs on hardware you do not own
It is worth being precise about what actually happens, because this is where the data confidence comes from.
The model weights are a file. The provider delivers the model and its inference software to the platform under a commercial agreement. The platform deploys a copy on its own infrastructure and runs inference there. There is no forwarding of each prompt back to the provider at request time. If there were, the whole isolation story would collapse, because every prompt would touch the provider’s systems.
This is similar to the lifecycle of a container image. Someone builds it, publishes it, and a server somewhere pulls it and runs it. The image author does not see what the container does in production. Claude on Bedrock follows the same logic, with a much larger proprietary file: Anthropic delivers the model to AWS, AWS runs it on AWS infrastructure, and what happens during the request stays between AWS and its customer.
DigitalOcean Gradient: open models with data sovereignty
DigitalOcean Gradient takes a different approach for a different need. It hosts open-weight models, including Llama from Meta, Mistral, and DeepSeek, directly on DigitalOcean infrastructure. When you call one of those DigitalOcean-hosted models, your prompt goes to DigitalOcean’s API and inference runs on DigitalOcean’s hardware. The model authors are not in the inference path.
There is an important nuance. Gradient also offers access to commercial models from providers such as Anthropic and OpenAI, but in that case DigitalOcean acts as a pass-through to the original provider. DigitalOcean says it does not store inputs or outputs for any models, and says customer data submitted to DigitalOcean-hosted models is not used to train, retrain, or fine-tune models on the DigitalOcean platform, nor shared with third parties for those purposes. For sovereignty discussions, this article is about the DigitalOcean-hosted open-model side: Llama, Mistral, and DeepSeek running on DigitalOcean infrastructure. That is where the in-perimeter architecture applies most directly.
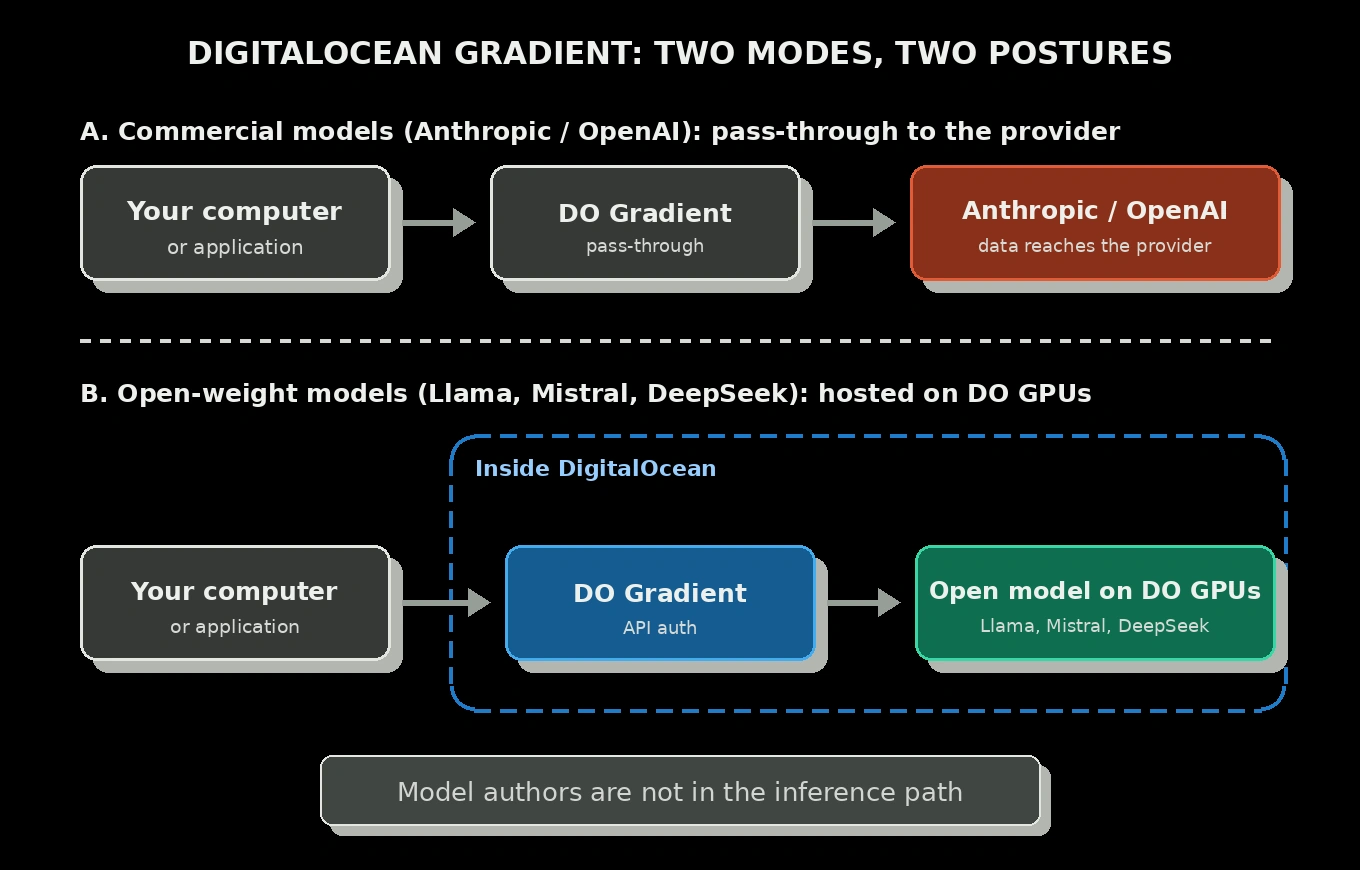
So Gradient is not a Bedrock competitor. Bedrock solves “I need a frontier model and data sovereignty.” Gradient with open models solves “I need a competent model for this specific task and data sovereignty without leaving a single cloud perimeter.” Different problems, different products.
Matching your data to the right option
The safeguarding strategy is straightforward once you classify what you have.
Public or low-sensitivity material works on either option. Pick by quality needs and budget. If the task is hard and quality matters, use Bedrock with Claude or similar. If the task is moderate and budget matters more, use Gradient with an open model.
Regulated or genuinely sensitive material needs more care. If the task requires frontier quality (deep reasoning, complex synthesis, agentic workflows), use Bedrock with a Regional or Geographic option pinned to a geography you accept. Your data stays inside AWS, the model provider does not see it, and you can prove residency to auditors. If the task can be served by an open model (extraction, classification, RAG over documents, internal support drafting), use Gradient with a DigitalOcean-hosted open model. Your data stays in DigitalOcean’s inference environment, no separate model author enters the request path, and you typically pay less per token.
The mistake is skipping classification and routing everything to whatever is easiest to integrate, then discovering later that some of it should not have gone there.
Use cases that fit this model
A few concrete examples to make this real.
A company building an internal document assistant over policy files. Retrieval over a private knowledge base, answers drafted by the model. Frontier-tier quality matters if the questions are complex; an open model works fine if the questions are standard.
A support team using a model to draft replies to incoming tickets for a human to review. An open model on Gradient often suffices, and the cost difference matters at volume.
A development team using a coding assistant scoped to an internal codebase. Frontier models on Bedrock when the work involves complex architectural reasoning; open models on Gradient for routine code review and boilerplate generation.
A batch job that classifies documents or extracts structured data overnight. Open models are usually enough, and batch pricing on supported workloads can cut the bill further.
A researcher or independent consultant on a three-month engagement with confidential client data. This is the case where managed inference earns its name. The researcher does not want to buy GPUs for a temporary project, and the client does not want data leaving a controlled perimeter. If the analysis requires frontier reasoning (complex synthesis, nuanced judgments, multi-step argumentation), Bedrock with a Regional option inside the client’s jurisdiction is the right call. If the work is more mechanical (structured extraction, pattern detection in transcripts, summarization), an open model on Gradient costs a fraction and can keep the inference path inside DigitalOcean. Once the engagement ends, no infrastructure is left running and no hardware purchase has to be amortized.
Each of these is a bounded project. None of them justifies operating a GPU cluster by itself.
The cost exercise
Numbers make the decision concrete. Take a mid-size company running an internal document assistant. Assume 1,000 queries per day across the company, each query using around 4,000 input tokens for the system prompt plus retrieved context, and around 600 output tokens for the answer. Over a 30-day month, that is 120 million input tokens and 18 million output tokens.
| Option | Input ($/M) | Output ($/M) | Est. monthly cost | Where the data lives |
|---|---|---|---|---|
| Bedrock — Claude Opus 4.7 | $5.00 | $25.00 | ~$1,050 | Inside AWS, zero operator access path |
| Bedrock — Claude Sonnet 4.6 | $3.00 | $15.00 | ~$630 | Inside AWS, zero operator access path |
| Bedrock — Claude Haiku 4.5 | $1.00 | $5.00 | ~$210 | Inside AWS, zero operator access path |
| DigitalOcean — hosted Llama 3.3 70B | ~$0.65 | ~$0.65 | ~$90 | Inside DigitalOcean |
| Self-managed — one NVIDIA H100, 24/7 | n/a | n/a | ~$2,400–$5,000+ | Your own environment |
A few things jump out. The same workload can range from about $90 to about $1,050 a month just by changing the model tier. Defaulting to the most powerful model is the most common way to overpay. The self-managed GPU row is a fixed cost you pay whether the machine is busy or idle. At this volume, it lands above the managed options, and a single H100 does not give you access to a proprietary frontier model anyway because those weights are not available for self-hosting. The H100 range depends on provider, region, on-demand versus reserved pricing, storage, networking, and operations.
For the researcher case the math is even more striking. A consultant processing 500 documents over three months might generate 5 to 10 million tokens total. On Sonnet 4.6 through Bedrock, that usually lands in the tens of dollars for extraction or summarization workloads, and can move into the low hundreds if the workload is output-heavy or runs repeated passes. On Llama 3.3 70B through Gradient, the model-token bill is usually under ten dollars before any extra platform, storage, or orchestration costs. Either way, it costs less than running an H100 continuously for a short engagement.
Two caveats keep the table honest. First, prompt caching can sharply reduce the input portion when the system prompt and stable context repeat. After you write the cache, reads can cost a fraction of normal input tokens. Second, batch processing can reduce the token bill for workloads that tolerate minutes of latency. On the other side, a managed knowledge base adds costs for embeddings, vector storage, guardrails, or observability. At low volume those fixed costs can outweigh the model tokens. Regional, Geographic, and Global routing options can also price differently. AWS describes Global Cross-Region inference as offering about 10% cost savings versus Geographic Cross-Region, while Anthropic documents separate data-residency multipliers on its own platforms. Confirm the current pricing page before you budget.
Where this is going
The direction of travel is documented in current rate cards, official announcements, and verifiable infrastructure rollouts.
Frontier model prices have fallen sharply at the top tier. Anthropic’s current pricing page lists prior Opus 4-tier models at $15 input and $75 output per million tokens, while Claude Opus 4.7 sits at $5 and $25 per million tokens. That is a 66.7% reduction at the premium tier. Sonnet and Haiku also provide lower-cost tiers, which makes it unnecessary to use the most expensive model for every task. The economic argument for self-hosting a frontier-equivalent model gets weaker as managed inference improves.
Sovereign infrastructure is being built, with honest gaps that must be checked at design time. AWS launched the European Sovereign Cloud as a physically and logically separate partition in Brandenburg, Germany, backed by a €7.8 billion investment. AWS says Bedrock is included among the services available in that sovereign environment. The important practical point is that service availability and model availability are not the same thing: when designing a sovereign Bedrock architecture, verify the current model catalog in the official AWS capabilities matrix before committing.
Endpoint and routing options have become first-class architectural concerns. Bedrock documents In-Region, Geographic Cross-Region, and Global Cross-Region options for Claude Opus 4.7. Two years ago this distinction barely existed in product discussions. Today it is one of the first decisions you make after choosing the model itself.
Capability that used to be premium is becoming default. Anthropic’s pricing documentation says Opus 4.7, Opus 4.6, and Sonnet 4.6 include the full 1M-token context window at standard pricing. The same page also notes that Opus 4.7 uses a new tokenizer that may use up to 35% more tokens for the same fixed text. That makes measurement important before migrating workloads from previous versions.
The combined picture is straightforward. Renting frontier inference keeps getting cheaper. Residency and routing controls are becoming more granular. Self-hosting only makes sense in the narrow band where regulation, latency, or cost at extreme scale force the issue.
How to decide
A short framework to close. Classify your data sensitivity before anything else. Match each workload to the smallest model that does the job well instead of defaulting to the most powerful one. Choose the platform based on where the data is allowed to live: Bedrock with a Regional or Geographic option for sensitive frontier-model work, or a DigitalOcean-hosted open model on Gradient when the task does not require frontier quality. Start on pay-as-you-go pricing and optimize later with caching, batching, and routing once you see real usage.
Owning GPUs only makes sense at sustained high volume, under very specific latency or cost requirements, or under an absolute data isolation obligation. For a company with one well-defined project, or a researcher with a confidential engagement, managed inference is the right starting point. The data can stay well protected as long as the architecture is chosen before the first prompt is sent.
By: Cesar Rosa Polanco - Written from a real experience, with artificial intelligence used as an editorial support tool.