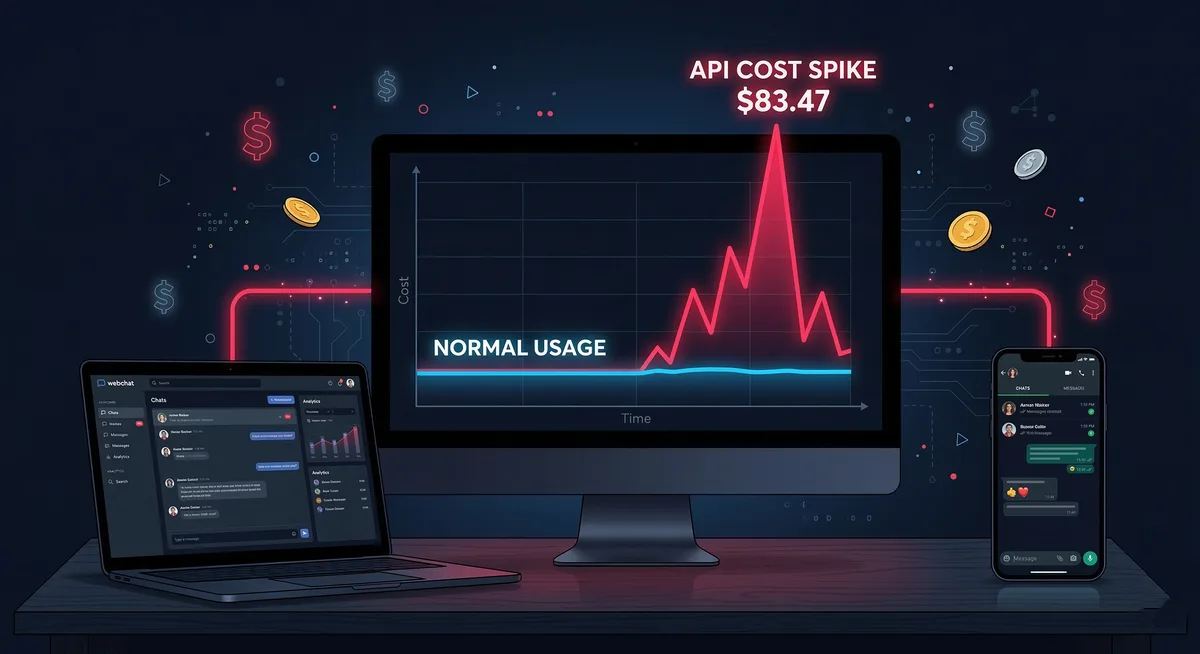
TL;DR: Gasté $83 en llamadas API a Claude en un solo día. Mi uso normal es $3-5. Esto es la historia de qué pasó, por qué pasó, y cómo lo arreglé.
El Despertar Rudo
Era una mañana normal. Café en mano, reviso el dashboard de Anthropic para ver el uso de API del día anterior. Esperaba ver los usuales $3-5 dólares.
$83.47
Pensé que era un error. Refresqué la página. Seguía ahí. Un spike masivo en el gráfico, como el pico del Everest comparado con las colinas normales de los días anteriores.
70 millones de tokens procesados en 24 horas. Mi día normal son 3-5 millones. Esto fue 14 veces más.
El Contexto (literal)
Uso OpenClaw con Claude Sonnet 4.5 como mi asistente de IA personal. Maneja mis emails, procesa facturas, escribe artículos para este blog, monitorea mi watchlist de acciones, y básicamente actúa como mi segundo cerebro.
Si no estás familiarizado con OpenClaw, consulta cómo lo implementé desde cero en Implementando OpenClaw: Asistente AI Autohospedado y luego cómo lo expandí en OpenClaw: Parte 2.
Lo tengo conectado por dos canales:
- WhatsApp (móvil, siempre conmigo)
- Webchat (escritorio, cuando trabajo)
Ambos comparten la misma sesión: agent:main:main. Eso significa que toda la conversación histórica se carga cada vez que envío un mensaje, sin importar por qué canal.
Y aquí fue donde me metí en problemas.
La Autopsia
SSH al servidor, revisar logs, hacer cálculos.
Los Números Fríos
9 de marzo de 2026:
- 1,912 llamadas API a Claude
- Context size promedio: 130,000 tokens
- Pico máximo de context: 157,000 tokens
- Session transcript size: 2.4 MB sin comprimir
Para los no técnicos: imagina que cada vez que le dices algo a tu asistente, él tiene que releer TODO el libro de conversaciones desde el principio para responderte. Y ese libro tiene ahora 2.4 MB de texto.
Culpable #1: Context Bloat
Mi sesión llevaba días sin limpiar. Cada mensaje, cada archivo leído, cada búsqueda, se acumulaba. El contexto había crecido a 157k tokens - casi el 80% del límite de 200k de Claude.
Cada mensaje mío, por simple que fuera (“¿qué hora es?”), cargaba 157k tokens de historial antes de procesar mi pregunta.
Pricing de Claude Sonnet 4.5:
- Input: $3.00 por millón de tokens
- Output: $15.00 por millón de tokens
- Cached input: $0.30 por millón (90% más barato)
Incluso con caching al 94%, un contexto de 157k se vuelve caro rápido:
157k tokens × $0.30/1M (cached) = $0.047 por mensaje solo en context
1,912 mensajes × $0.047 = $89.86 en puro context inputCulpable #2: Ping-Pong Entre Canales
Estuve usando WhatsApp y Webchat al mismo tiempo sin darme cuenta del efecto. Mensajes por WhatsApp en la mañana, webchat en la oficina, alternando todo el día. Cada canal cargaba el mismo context gigante.
Los logs no mienten:
Mar 09 10:26:38 - webchat session start
Mar 09 10:27:48 - whatsapp message
Mar 09 12:05:41 - webchat message
Mar 09 12:08:05 - whatsapp message
Mar 09 12:11:13 - whatsapp message
Mar 09 12:13:59 - webchat messageY las banderas rojas estaban ahí: respuestas de 5-10 segundos para mensajes simples, logs con forceFlushByTranscriptSize=true, y warnings de tokenCount=157344 rozando el límite. No les presté atención.
Por Qué Escala Tan Mal
Comparación rápida:
Día normal (context 30k):
100 mensajes × 30k tokens = 3M tokens input
Con caching 94% ≈ $1.50El día del desastre (context 157k):
120 mensajes × 157k tokens = 18.8M tokens input
Con caching 94% ≈ $11 input + $72 output = $83El context es un multiplicador de costo. Cada token de historial se paga en cada mensaje que envías.
Cómo Lo Arreglé
Acción Inmediata
1. Budget Alert - Anthropic Console → Settings → Billing → alert de $15/día. Nunca más me despertaré con un gasto sorpresa.
2. Limpié la Sesión
openclaw session:clear agent:main:mainContext volvió a ~0. Session fresca.
3. Regla de Un Canal - Solo un canal activo a la vez. PC → webchat. Móvil → WhatsApp. Nunca ambos simultáneos.
4. Limpieza Automática - Cron job cada domingo:
0 0 * * 0 openclaw session:clear agent:main:mainPrevención a Largo Plazo
Context: Monitoreo semanal, alert si >100k tokens, limpieza proactiva.
Modelos: Heartbeats y tareas simples con Haiku ($0.25/1M vs $3/1M). Sonnet para lo que realmente lo necesita.
Canales: Webchat como principal, WhatsApp solo para emergencias móviles, testing en sesiones separadas.
Lecciones
Context is King (y Villain)
El context window es tu mejor amigo y tu peor enemigo. Te da continuidad - la IA no empieza de cero cada vez. Pero crece sin control si no lo vigilas, y cada token se paga en cada mensaje.
Regla nueva: Context >100k = tiempo de limpieza.
Arquitectura Importa
Múltiples interfaces compartiendo el mismo context masivo = costo multiplicado. La solución real a largo plazo: sesiones separadas por canal, context sharing selectivo, rate limiting.
Monitoring No Es Opcional
Si no mides, no puedes optimizar. La parte más cara no fueron los $83 - fue el tiempo sin darme cuenta. Si hubiera configurado alerts desde el día 1, me habría enterado a las 2 PM en vez de a las 8 AM del día siguiente.
El Día Después
Hoy, 10 de marzo, mi uso está en $3.47. Normal. Context size: 36k tokens. Budget alert: configurado.
La ineficiencia puede convertir algo barato en caro muy rápido. Pero $83 por aprender arquitectura de costos de IA, debugging de sistemas complejos, y la importancia del monitoring - es matrícula barata.
¿Volvería a pasar? No si puedo evitarlo. Pero si pasa, sé exactamente qué buscar y cómo arreglarlo.
Y ahora tú también.
Este artículo es parte de mi serie documentando experiencias reales construyendo con IA. No teoría, solo batallas en las trincheras.
Por: Cesar Rosa Polanco - Basado en un caso real, con apoyo editorial de inteligencia artificial.